The Need and Types of Activation Function
Hello World!!! In this blog I will talking about the activation function, their need and their types
Neurons and its functions

Neuron has the task to process and transmit information. Dendrites receive information in the form of electrical impulse, The cell processes that information. The electrical signals are then send out to other neurons via axons. The junction where two neurons meet is called a synapse. Once the electrical signal reaches synapse, neuro transmitter is released which is partially electrical and partially chemical, this transmitter will trigger the next electrical signal in neuron. So these neuron send filtered information to the a specific part of brain which takes the call by again looking at the cumulative decision taken by other neurons. For example: If Lionel Messi injures his toe while playing football, the sensory neurons of the toe will release electrical signals which will get transmitted to other neurons via axons, and will reach the brain. The pain segment of the brain will get activated and will make Messi feel it.
The image on the right is the image of artificial neuron, which takes in information from other neurons i.e. x0, processes them by multiplying the weights to the inputs at synapse i.e. w0x0 and combines all those information i.e.

Then the final output is passed via an activation function to add non linearity to the output and finally the output is send to the neuron connected to it.
Why do we need Activation functions?
Activation functions adds non linearity to the model, so the question arises why to we need non linearity? Any neural Network without an activation function is a linear model i.e. its graph is a straight line i.e. a polynomial function of degree zero or one.

The dataset was very simple and could be classified into two categories using a straight line, but once the data becomes complex like

Here we can see that we cannot segregate the data using a straight line and we need a curve, hence we need something via which we can create a curve because the network otherwise is the weight sum of the input with biases. hence we add an activation function.

Once we add non linearity, it can easily segregate the data.

Neural Networks are called Universal Function Approximator i.e. they are able to learn anything. Everything in the world can be represented in an equation, theoretically it is possible but practically it is very difficult. And of Neural Networks to lean everything, they should have the power to derive any equation and which can be only possible if there is non linearity.
Different Types of Activation Functions:
There are various types of activation functions, the most common ones are :
Sigmoid Function
It is one of the most historic activation function, The task of this function is to squeeze the incoming input to a range of 0 or 1 i.e. Large negative numbers will be close to 0 and large positive numbers will be close to 1.
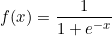
This function has the following problems:
- It is prone to Vanishing Gradients problem: If the gradients are small in the layers, in the back propagation step when the local gradient is multiplied with the back propagation output, the resulting gradient will grow smaller and smaller and will eventually die, hence the initial layers will not learn anything.
- It is Prone to Exploding Gradient Problem: If the initial weights assigned to the neurons are high, and gradients are also high, it may lead to very high weights, resulting is no learning.
- The outputs are non Zero centered: Lets say there are two parameters w1 and w2 plotting in X and Y axis respectively.
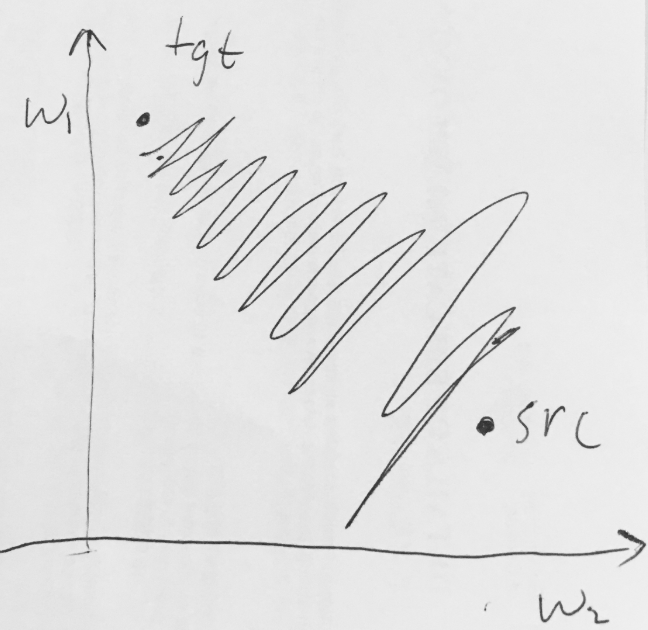
If both have same sign so the learning can either be in north east direction or south west direction. Hence to reach from source to target the way is in zigzag manner slowing the convergence.
4. It also leads to slow convergence i.e. our network will learn slowly.
Hard Sigmoid Function
It is another variant of sigmoid function saving computation cost as no exponential values exist in the equation which is needed to be calculated here.
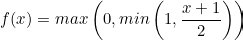
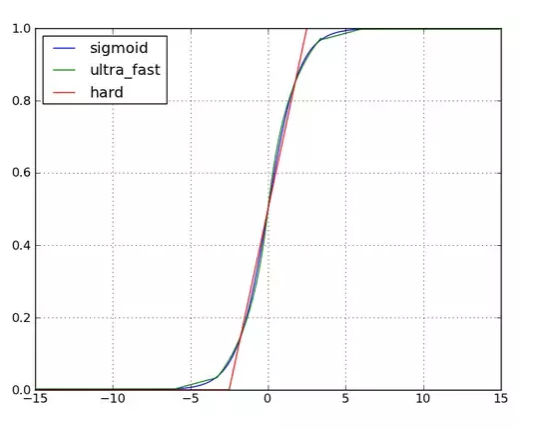
The disadvantage of this function is that they are more error prone as they are approximating sigmoid function, but it can be rectified using more training as they are faster to train. The rest disadvantages remain the same of that of sigmoid function
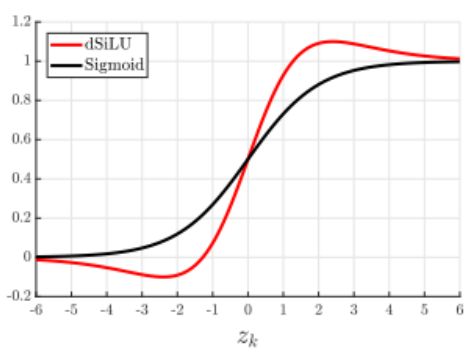
Sigmoid- Weighted Linear Units (SiLU)
It is approximation function for reinforcement learning. It is defined as sigmoid multiplied by its input.
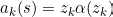
In the equation, s is the input, α is the sigmoid function and zₖ is defined as below
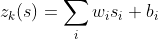
here wᵢ and bᵢ are the weights and bais of the hidden layer.
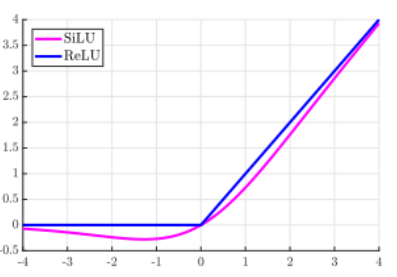
Unlike ReLU, the function doesn't increase monotonically, instead has a global minimum value of approximately i.e. -0.28 for zₖ nearly equal to 1. The function demonstrates self stabilizing property i.e. when it reaches global minimum i.e. its derivatives is 0, it provides a “soft floor” on the weights acting as a regularizer to stop the learning of weights of higher magnitude.
The function is for reinforcement learning algorithm, therefore limits its scope of usage in only reinforcement learning applications and research. Though the function has been tested on CIFAR 10/100 datasets outperforming other activation when ran over 5 architectures, but no tabular comparison has been made in the paper stating the results.
Derivative of Sigmoid-Weighted Linear Units
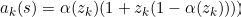
The equation is the derivative of Silu Function
TanH
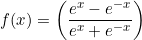
It is also called hyperbolic Tangent function. It is zero centered and squeezes the values between -1 to 1.
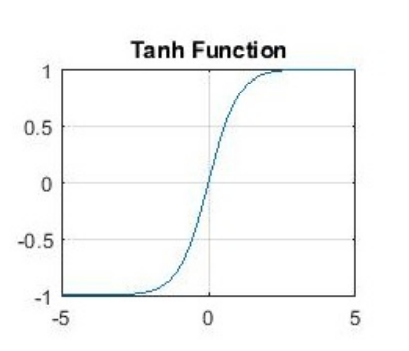
It is also one of the very old activation functions. It is better than sigmoid function as it gives better training out. The main reason is because it produces zero centered output which helps back propagation to converge faster. Here the function produces output in negative so even if both the weights are negative, their multiplication will result in a positive value which will give a direction rather than going in a zigzag manner as shown for sigmoid.
The function still is not able to solve the vanishing gradient problem
Hard Hyperbolic Function
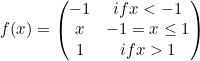
Softmax
This activation function is used to produce probability like distribution. It produces an output in the range 0 to 1, and it sums everything to 1.
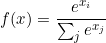
It is used for multivariate classification. This function exaggerates the output by computing in such a way that the predicted class will have a high confidence value as compared to others. Due to this exaggeration, it is not used in medical domain as there we want exact values because the cost of a wrong prediction is very high.
Softplus [2001]
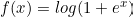
It is mainly used in regression problems.
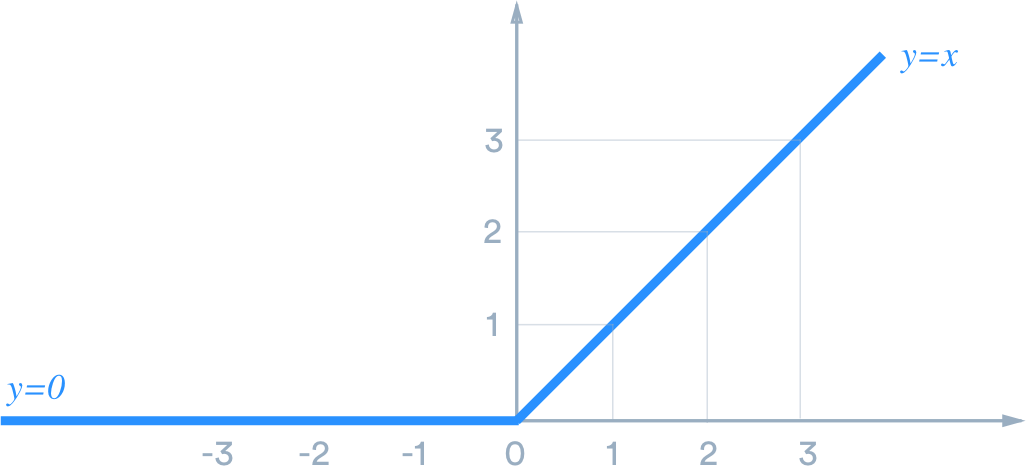
Relu [2010]
From the losses of Tanh and Sigmoid Function, ReLU was born. It is also called as Rectified Linear Unit.
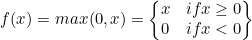
It is one of the activation function which is very common in most of the state of the art algorithms.

This is a very positive function, it says I want to ignore all the negative values I see and I will only keep positive values.
This function has various advantages as:
- It is extremely fast, as here we just need to compare one bit i.e. we all know that values in computer are stored in bits. Each number has a signed bit at the starting indicating whether it is positive or negative, therefore just by checking one bit, our job is done rather than performing all the exponential operations.
- ReLU solves the vanishing gradient problem as there are no negative gradients going forward.
ReLU also suffers from some disadvantages like
- It is very prone to overfitting as compared to other activation functions, but it can be rectified using regularization techniques.
- As the negative neurons are turned to zero, in back propagation sometimes they are not updated, these neurons then die and results to Dying ReLU Problem.
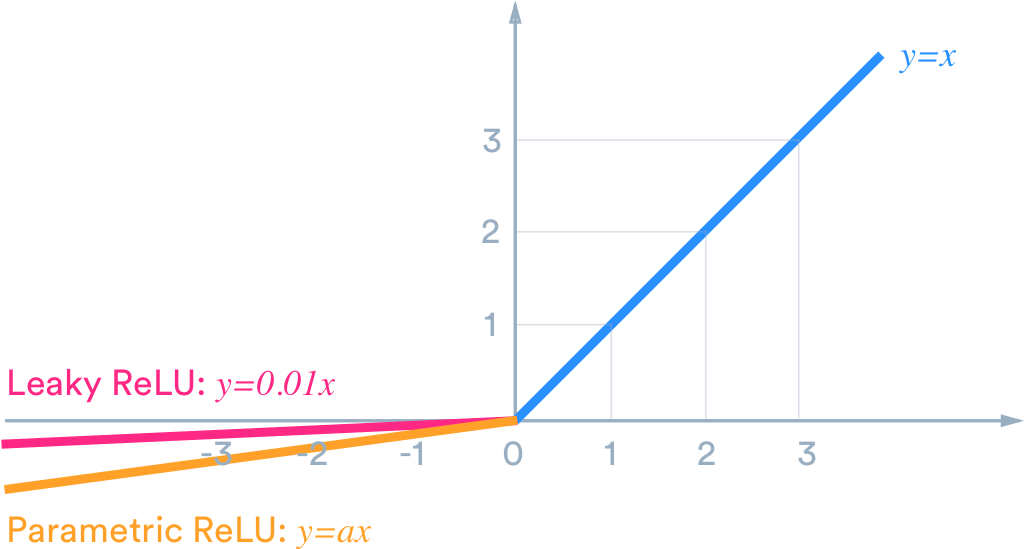
Leaky Relu [2013]
Leaky ReLU was made to solve the dying RelU problem.

In Leaky ReLU, alpha parameter is introduced. It says that if negative values come in we will not remove them, but will have some of it. Kind off one should also look at the critiques to improve 😋 rather than just looking at the positive feedbacks.
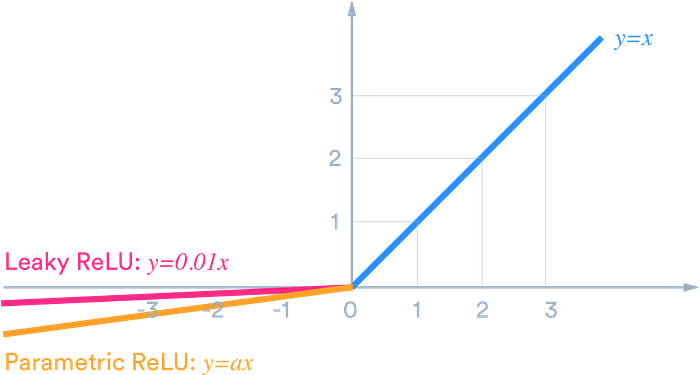
Here the α value is generally 0.01, or in the range of that.
The algorithm performs very much similar to ReLU giving identical results. Dying ReLU problem is not very common, so using LReLU over ReLU is still a question, as SOTA Algorithms uses RELU often.
Parametric Relu [2015]
It is another variant of ReLU. It is also called as PReLU
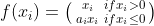
It has slight change as compared to LReLU and that is instead of α being fixed to 0.01 or something fixed by humans, we let the machine figure out what that value has to be. Hence when backpropagation happens, this value is also updated.
This function gave a huge performance advantage on large dataset. And this function led Machines to surpass human intelligence over Image Net Competition.
Randomized Leaky ReLU
It is a variant of Leaky ReLU also referred to as RReLU
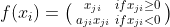
S-shaped ReLU [2015]
It is one more another variation of ReLU Activation function, This function is used to learn the convex and non convex functions
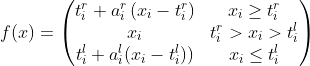
The convex world in the world where local minima is equal to the global minima(difficult to achieve) and in the non convex world the local minima is not equal to the global minima
The equation consists of three piecewise linear function with 4 learnable parameters. aᵢʳ is the slope for line on the right where as aᵢˡ is the equation of line on the left. tᵢʳ & tᵢˡ are the thresholds in positive and negative direction respectively.
This function was tested on State of the Art Algorithms of that time and gave improved results.
Softsign [2001]
It is an activation function which rescales the value to the range -1 to 1.
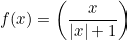
It is mainly used for regression type problems.
It is an alterative to tanh. The advantage of using thus function is that tanh converges exponentially where as softsign converges polynomially
ELU [2015]
Exponential Linear units are used to speed up the training of Deep learning
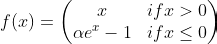
PELU [2017]
Parametric Exponential Linear Unit is a variation of ELU
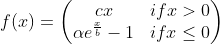
SELU [2017]
Scaled Exponential Linear Units is one more variation of ELU.
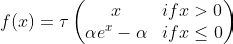
Maxout [2013]
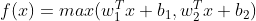
One major drawback of using Maxout is that it doubles the parameters used in training which results in more number of training parameters costing more training time and more computation.
Swish [2017]
It is one of the first Hybrid Activation functions, it is made from the combination of sigmoid function and input function.
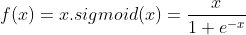
EliSH [2018]
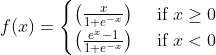
Hard EliSH
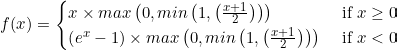
C ReLU [2016]
ReLU-6 [2010]
This is a special version of ReLU.
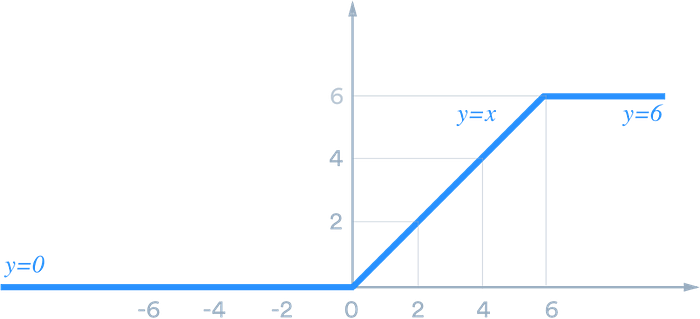
In this version, the upper bound is set to 6, why 6? Coz authors said it. They found it that by keeping an upper bound makes the network learn sparse features fasters, that means the model will converge faster.
References:
- Working of Neuron
- Why do we need Activation function segment snippets
- Types of Activation Function segment
If you liked the blog and found it useful, so give a clap and share it with your friends. If I missed out any important activation function, do let me know in the comments.

{kind=link}
{kind=link}
{kind=link}